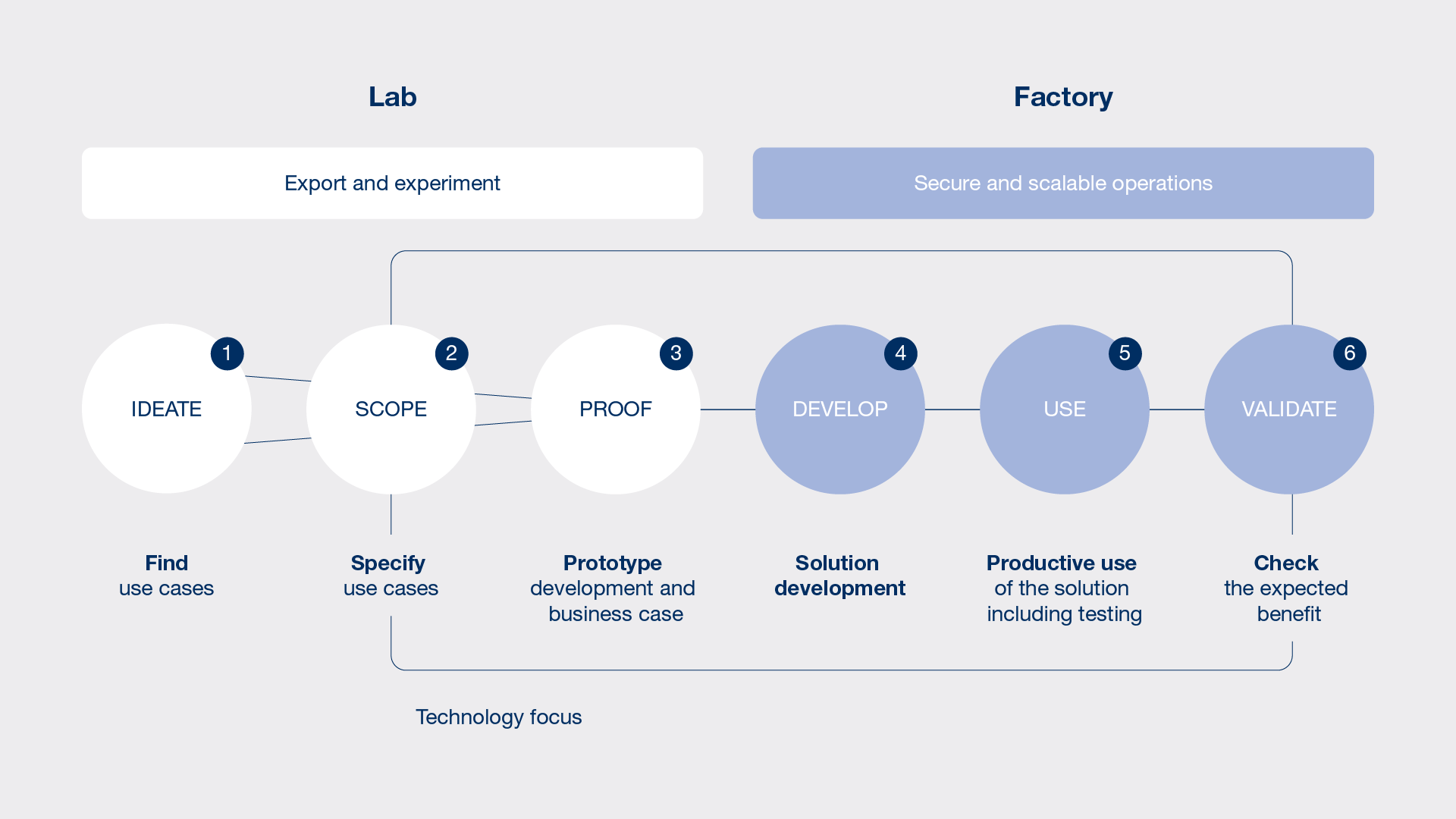
Löchte: Ich rate erstens zu einem Use-Case-Management, das bereits im Labor Ideen bewertet. Es untersucht, inwieweit sich aus Daten verwertbares Wissen im Sinne der Unternehmensstrategie und der Ableitung von Handlungsfeldern generieren lässt. Zweitens müssen Sie den Bereich und die Expertise von Data Science inhouse aufbauen. Drittens sollte der Datenzugriff zum Sammeln und Aufbereiten von Informationen einfach gestaltet sein – etwa durch Datalake-Lösungen –, die Rohdaten zur Verfügung stellen.
Rahimi: Zwar sitzen Versicherungen auf enormen Datenschätzen. Dennoch und viertens kommen auch sie nicht umhin, externe Datentöpfe in ihre Berechnungen einfließen zu lassen: etwa statistische Informationen zu Sterblichkeit, Geburten, Wetter und Entwicklung an den Finanzmärkten. Außerdem Daten zu Regionalität, Bebauungsstrukturen, Gartenanteil und viele Datenpunkte mehr. Ganzheitliche Integrationsplattformen, die neben Bestandsinformationen auch Social-Media-Daten, Geoinformationen und weitere externe Daten in ihrer Factory nahezu in Echtzeit verfüg- und verarbeitbar machen, sind ein weiterer Erfolgsfaktor.
Roth: In- und externe Daten helfen einzukreisen, wo Konsumenten mit Kundenpotenzial wohnen, wo Versicherer mit Stürmen und erhöhten Gefahren durch Umweltkatastrophen rechnen müssen und wo besondere Produkte aufgrund aktueller Gegebenheiten möglich sind. Außenstände im Zahlungsverkehr lassen sich gut visualisieren; Institute bleiben handlungsfähig. Richtig interessant wird es, wenn Banken und Versicherer prognostizieren, welche individuellen Bedürfnisse bei der Behandlung von Außenständen notwendig sind.